
Yita,新一代大数据高性能计算引擎
Yita并行执行模型
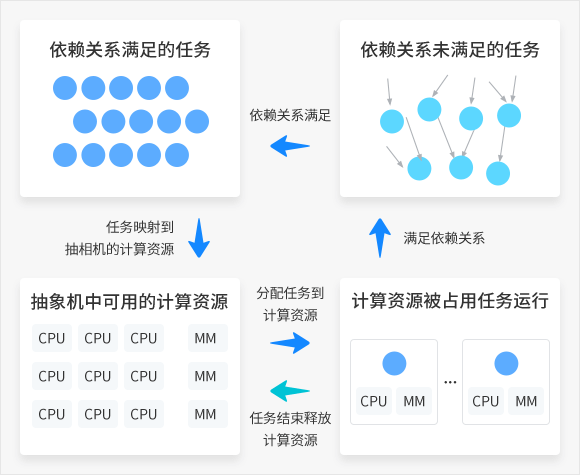
Yita特点和优势

计算加速


资源充分利用


节省成本


全面兼容


易于配置


可视化编程


自主知识产权

Yita适用场景

大数据海量实时高吞吐业务
应用于:工业制造、金融、汽车、餐饮、电信、能源、娱乐、疾控、政务、公安等。
大视频人/车/事件智能视频分析业务
应用于:安防、交通、社区、园区、商场、超市、学校等复杂环境。如智慧交通、智慧社区、智慧校园、环境监控、智能制造、无人零售、智能楼宇等。

Yita专利及奖励

国产大数据技术第一梯队



Yita AI:极简易用 ,极致性能,智能世界的基础底座
Yita AI基于Yita细粒度、分布式调度的优势,对主流深度学习框架进行封装和优化,通过将机器学习算法、深度学习算法和图计算算法等与Yita融合,实现多节点高性能分布式深度学习的人工智能框架。Yita AI具有丰富的深度学习算法和视频基础能力的封装,通过海量数据训练计算模型,极大地提高模型的识别准确率和训练效率,并提供极优AI能效比。Yita AI支持端边云分布式协同计算,一次开发,多处部署,更优流量分配。Yita AI支持全栈开放,极简应用开发,一键部署,业务快速上线。
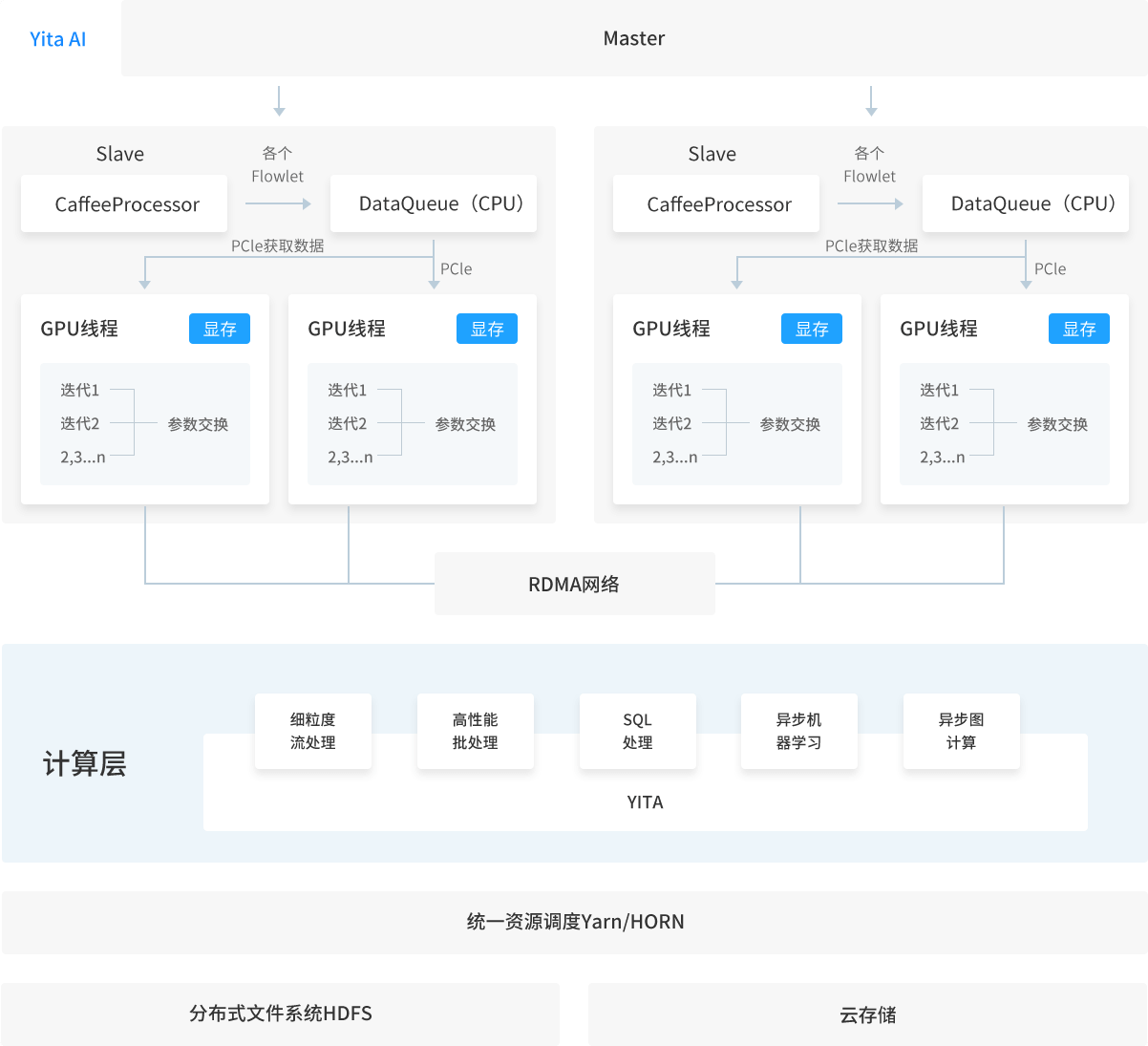
Yita AI:基于数据流理论的高性能DL深度学习集群
Yita AI并行计算包括模型并行和数据并行。模型并行是将训练的模型分割并发送到多个Worker节点上,多个Worker为一组训练一个模型;数据并行是将数据进行切分,然后将模型复本发送到各Worker节点,各Worker独立训练,通过参数服务(Parameter Server)进行参数交换。
数据并行采用分布式读取数据集,通过yita partition进行数据的切分,并把数据放入DataQueue中暂存。每一个slave计算节点会创建一个DLProcessor模型实例,DLProcessor会针对每个GPU设备启动一个线程,每个线程会从DataQueue中每次获取一批数据(mini-batch)进行训练。这时候GPU会通过PCIe总线与该slave节点的CPU进行交互,将CPU系统内存中的数据传输到GPU显存中,并且每个GPU会有相同的模型备份。PCIe链路可以由多条Lane组成,目前PCIe链路可以支持1、2、4、8、12、16、32和40个Lane,即×1、×2、×4、×8、×12、×16和×32宽度的PCIe链路。由于数据在节点的CPU到GPU设备拷贝需要占用I/O时间,所以设计在各GPU计算每batch数据时,由Yita AI的I/O模块采用流式缓冲方式,以达到用计算时间掩盖I/O的时间,最大化利用GPU的计算资源。
Yita AI的特点和优势
丰富的算法
自研深度学习框架
多任务识别算法
CPU、GPU异构资源调度
多机多卡、分布式训练
Yita AI应用场景

AI数据并行加速应用场景
智慧城市、智慧医疗、天文探索、石油勘探、智慧零售、智慧医疗、智慧金融、智慧交通等

中心AI推理场景
精准营销、医疗影像分析、视频分析、OCR等

云边计算融合场景
安防、交通、社区、园区、商场、超市等复杂环境。如智慧变电站、智慧交通、智慧社区、环境监控、智能制造、智慧营业厅、无人零售、智能楼宇等

AI快速开发、快速验证场景
开发者方案验证、高校教育、科学研究等

嵌入智能边缘设备场景
端侧实现目标识别、图像分类等,如智能摄像机、机器人、无人机等端侧AI场景中的图像分析、视频分析、图像分割、物体识别等